A man surveys his friends. He notes, with quiet satisfaction, that they are, on balance, a pretty sharp lot — the kind who read things, remember things, and can be trusted not to embarrass you at dinner. And yet, an alarming proportion of them have taken one look at this machine learning business and waved the white flag without (as far as one can tell) having been given a fair fight.
I was given the fair fight by Jeffrey L. Elman. He wrote my favourite paper, Finding Structure in Time. This is a guided read of it that aims to be accessible as I've found that even my friends in AI research proper have not heard of it (so what hope for the rest of us mortals).
The Problem, As It Were
Time underlies many interesting human behaviors. Thus, the question of how to represent time in connectionist models is very important. [...] It is inextricably bound up with many behaviors (such as language) which express themselves as temporal sequences. Indeed, it is difficult to know how one might deal with such basic problems as goal-directed behavior, planning, or causation without some way of representing time. The question of how to represent time might seem to arise as a special problem unique to parallel-processing models, if only because the parallel nature of computation appears to be at odds with the serial nature of temporal events.
What an odd way to start a paper on artificial intelligence, especially if you read academic output today. It's worth carefully examining why the treatment of time occupies any mind-space for the author. Elman writes Finding Structure in Time in 1990. This is at the height of the revival of connectionism.
Connectionist Models
You don't hear the word connectionist very often these days so it is worth talking about what it means for something to be a "connectionist model". When was the last time you had a word at the "tip of the tongue"? You almost know a word. This partial recall is much easier to explain if the brain's state at any given point is a series of distributed patterns that can be partially "activated".
To make it rather painfully obvious, if the brain stored concepts in single neurons (which we will simply and erroneously model as some unit of wet compute & storage), you would have a neuron for your grandmother, another for her wearing a hat, another for her at last thanksgiving and so on, infinitely. The foggiest notion of the old lady would require a lump of grey matter so vast that no creature born of woman could possibly possess. Of course, we still have zero clue exactly how real brains work and this is a bit of a caricature but the intuition is useful.
There's two ways of mentally modeling what a connectionist (or the phrase Elman uses, Parallel Distributed Processing — PDP) model does. The first is the implementation picture of it. This is the oft-seen neural network:

This is admittedly the most accurate visualization of it. The more intuitive one however is the geometric one. What a neural network does — even the more sophisticated ones — is lift inputs you give it into some high-dimensional space and then move it around in that space or through a sequence of spaces. Crucially, the precise movements are not programmed in, they are learned or reverse engineered from data (questions for which you already have the answer).
This makes immediate sense for "static problems" e.g. classifying some input, completing a pattern. It's not immediately obvious, however, what you do with time, which is essential to speech, text, action, planning, reasoning. A connectionist model simply takes some input, manipulates it and produces an output. There is no point at which you can supply more information about what happened after the output that allows the next output to be influenced by the previous one.
Symbolic Approaches
This contrasts with the symbolic approach. If you have no training in computer science, you will almost definitely independently arrive at something approximating symbolic AI if you were tasked with designing an artificial intelligence. Put simply, the symbolic approach boils down to a massive knowledge bank of explicit rules that look much like "if X, then Y". We don't do explicit enumeration, of course — the rules we want are compact, compose-able, generalized rules that can ideally handle an unbounded number of cases. An example of such a rule would be the Law of Excluded Middle (a proposition can be true or not true; it cannot be both). There are two issues with this:
- The sheer number of rules a computer would need to exhibit even simplistic behaviour would be very large. This is very real engineering difficulty.
- The decision tree becomes extremely complex and unwieldy. Inference becomes a massive search and deduction problem.
- Improvement becomes an engineering problem rather than a teaching problem.
In the late 1980s, a great big objection to connectionism was that, if neural networks cannot represent temporal structure, they cannot be models of language, planning, causation or goal-directed behaviour. If they cannot do any of these things, they cannot model or approximate intelligence.
Why can't neural networks simply represent temporal structure, you ask? Well, a neural network is simply this equation repeated many times over, in parallel:
is what's called the weight matrix. It looks like a grid of numbers — although I personally find this representation of it to be distasteful. It's better viewed as a transformation of some space; I mean this quite literally, you can take the 3D space that you inhabit and apply a relatively trivial weight matrix (read: linear transformation) to it and end up with a stretched, warped, surrealist version of your world.
is a mathematical contrivance called a bias. Its primary utility is the handling of situations where happens to be 0. If is 0 and there is no bias, you have a situation where can't be anything other than 0; thereby ensures that can be anything it wants to be when it grows up — which sounds startlingly like something my parents would repeat with admirable frequency until reality intervened.
Now, where would you plug in time, here? You either do the computation or you don't. And once you do it, there is no room for "state" in the equation and what happened before is promptly forgotten. You could smuggle it into but then you have to wait until every member of the sequence arrives before processing it — we don't process the world that way.
Time
How can a system whose internal operations are parallel model a world whose events unfold serially in time?
Let's talk about the naive answer to the problem.
In parallel distributed processing models, the processing of sequential inputs has been accomplished in several ways. The most common solution is to attempt to “paralilize time” by giving it a spatial representation. However, there are problems with this approach, and it is ultimately not a good solution. A better approach would be to represent time implicitly rather than explicitly. That is, we represent time by the effect it has on processing and not as an additional dimension of the input.
When Elman was writing in 1990, it was still not quite clear how computers could be taught to understand human language. We knew that words could be represented as points in some high dimensional space — a vector with each number in it describing the -ness of some property.

But we did not know what to do with time.
This seems unusual considering in our minds, time is ever-present yet never-noticed. There's nothing inherent about a calculator, for instance, that gives it the ability to perceive time. Notions of order must be taught or built into your computation in some sense. The trivial solution is to take the entire sequence, freeze it and lay it out in space, as discussed. We put the first event in slot one, second in slot two and on and on (of ). This is convenient to write down; anything but in implementation.
- The entire sequence has to be available before the computation can proceed.
- The model now needs enough slots for the longest possible slot it is possible to encounter.
- Two identical events shifted slightly in time now become different things to the machine.
Elman chooses to do something else:
The spatial representation of time described above treats time as an explicit part of the input. There is another, very different possibility: Allow time to be represented by the effect it has on processing. This means giving the processing system dynamic properties that are responsive to temporal sequences. In short, the network must be given memory.
This may seem like a trivial insight. Of course, the bally thing needs memory. We have memory — it follows that a supposedly intelligent model would require memory. But it's certainly not obvious how best to go about implementing memory in connectionist models. Elman's solution is to express time as a function of the internal state of the model. It's worth mulling over what that means.
To understand what Elman means by "expressing time as a function of the internal state," we have to briefly look at how computers traditionally handle memory.
If you ask a computer to remember something, it writes that information into a literal, physical location on a silicon chip. When it needs the information again, it retrieves it. Time, in this paradigm, is a sequence of discrete datum stacked one after the other.
But human memory doesn’t feel like that. When you read the end of a sentence, you are not consciously accessing a datum containing the beginning of the sentence. Instead, the beginning of the sentence has altered your current state of mind, and you process the end of the sentence through the lens of that altered state.
This intuition leads the author to propose a modification to the standard neural network. Alongside the input layer, the hidden layer, and the output layer, he adds the Context Unit.
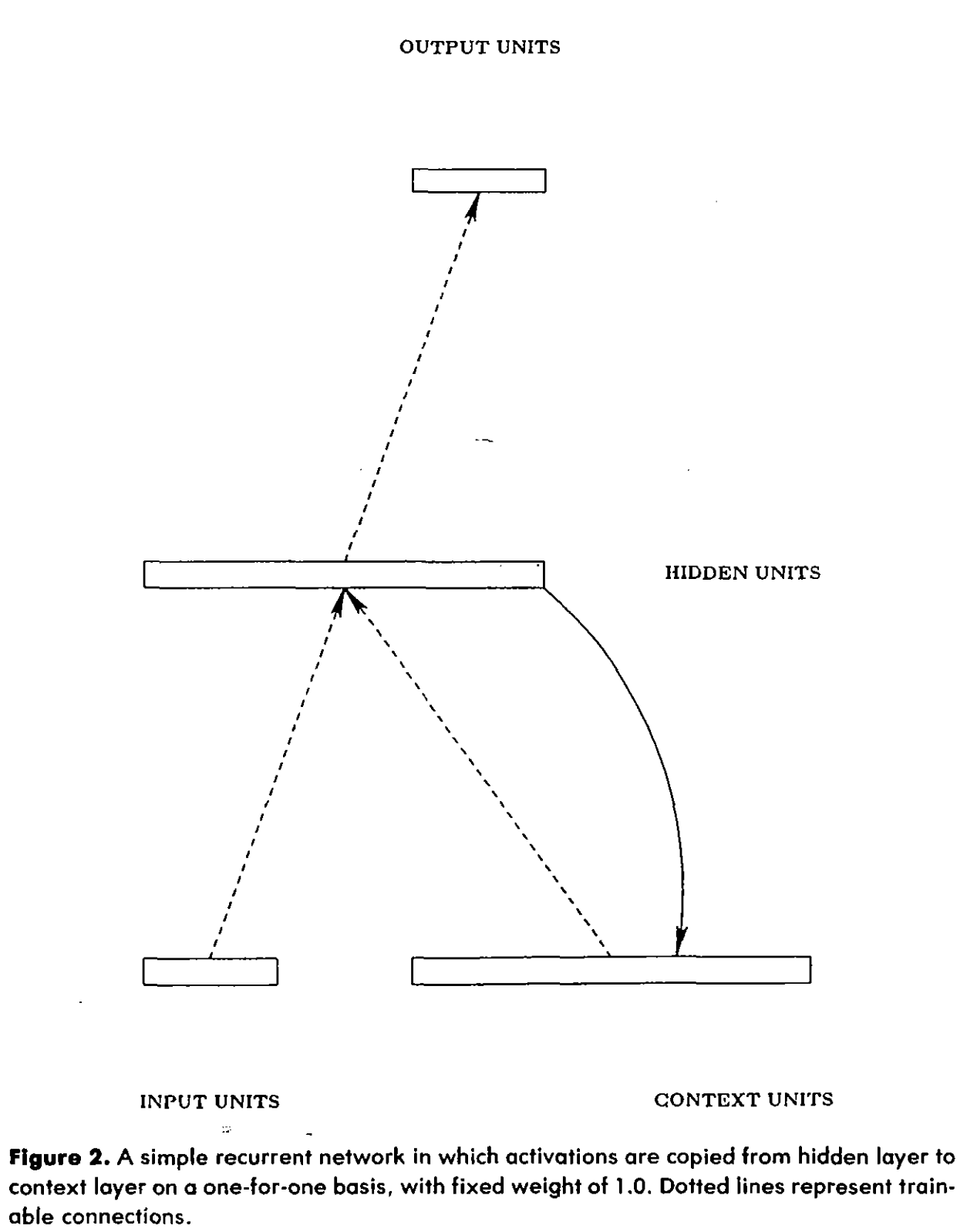
Elman Network Architecture: Context units provide a memory of previous hidden states, making the network responsive to temporal sequences. Figure taken from the original paper.
- At time step 1, you feed the network an input.
- Said network processes it through its hidden layer and supplies an answer.
- Before it moves on, it makes a copy of the answer, placing it in the context unit.
- In any other time step that is not the first time step, you feed the network the latest input as one does. But this time, the network looks at the new input plus the context units — which contain some mish-mash of past events.
The network now has a dynamic memory. It is no longer just looking at a static picture; it is experiencing a continuing present colored by the past. Elman called this a Simple Recurrent Network (SRN). Today, we just call them Recurrent Neural Networks (RNNs), and they are one of the staples of the modern AI revolution.
But having built the machine, Elman had to prove that it could actually perceive time and extract structure from it.
Temporal XOR
XOR is a trivial operation for humans. It is simply the exclusive variant of OR.
| A | B | OR (either A or B is True) | XOR (exactly one but not both of A and B is True) |
|---|---|---|---|
| True | False | True | True |
| True | True | True | False |
| False | True | True | True |
| False | False | False | False |
If I give you a sequence of Trues and Falses at random, you can compute the XOR operation on the latest two ad infinitum without expending much effort. The unfortunate thing is that simple connectionism simply cannot do the same thing. Consider a simple model that takes two numbers, either 0s or 1s and then provides an indication as to whether the next number is going to be a 0 or a 1.
We can expand this to:
Let's say:
- , if the next number in the sequence is True, which we encode as 1
- , if the next number is False, which we encode as 0
If the equation above represents a simple connectionist model that is capable of calculating XOR, then we have a number of conditions that follow:
- , if the result of XOR on the last two inputs is True
- , if the result of XOR on the last two inputs is False
We can actually plug all possible inputs in and arrive at the following conclusions (we substitute for )
- implies (output 0)
- implies (output 1)
- implies (output 1)
- implies (output 0)
We add (2) and (3):
But this directly contradicts (4). We can't have and simultaneously. If the equations are too dull to brook, consider the geometry of the problem:

Can you draw a straight line such that all the cases where True is the next item in the sequence fall on one side and all the cases where False is the next item in the sequence fall on the other? The only real way to do it is to have an intermediate step where you move the input points in space until they're cleanly separable or, as Minsky and Papert put it, linearly separable. You can solve this by adding another layer of some computation (with different weights, ) i.e. a multilayer perceptron.
Elman opted to first test his Simple Recurrent Network on the XOR problem. The network takes 1 bit at a time (unlike the model we just discussed, which takes the last two inputs simultaneously). After training with a 3000 bit error stream, we have a functioning model.
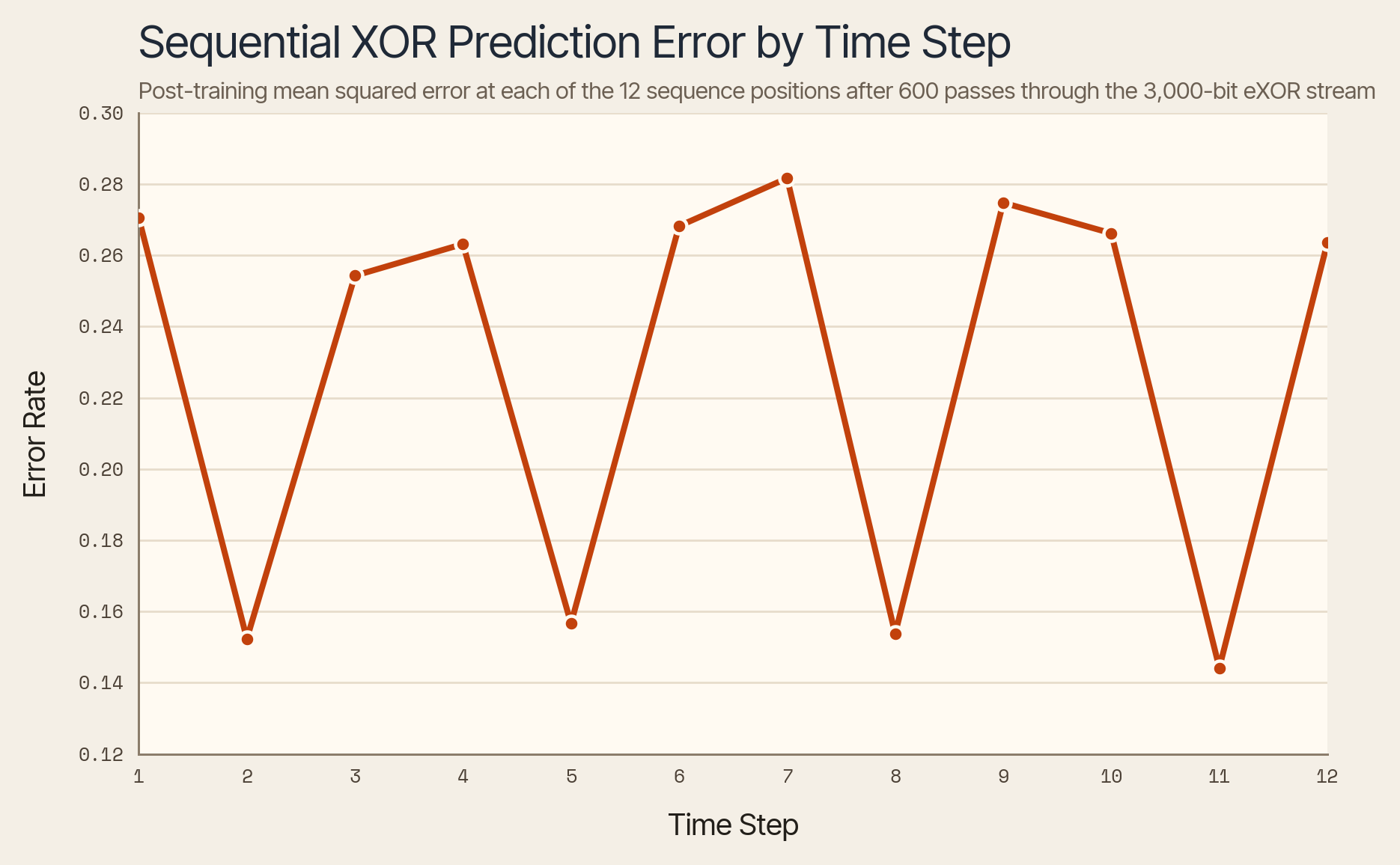
Figure: Network predictions versus ground truth on the XOR sequence (after Elman, 1990).
This may look like defeat but it is doing precisely what it is supposed to. The network is trained to predict the next bit at every timestep so the predictability alternates. When you feed it the first bit of the XOR operation, the next bit is truly random. It's only when it sees the second bit that it can actually calculate rather than guess what the next bit is to be.
The nice thing here in an age when precious few serendipities were to be had is that the mere act of the network seeing the XOR pattern allowed it to reliably pick up the mathematical rule behind it.
He that breaks a thing...
Elman stops at a cursory examination of what the model is actually doing. We, however, being gremlins seized by an unaccountable fit of scientific curiosity, will try to crack open the thing and study it. What is it actually doing?
This is a question that occupies no small amount of cerebral real estate in obscenely expensive parts of San Francisco. What do these networks actually do? The answer to this question is not easily had for even the most trivial of networks. In fact, we disagree on how to even go about collecting these answers. The physical world yields rather readily to reductionism; much as Gandalf may disapprove, taking apart a thing is a first-rate method to understanding its workings. We can apply the same instinct to these models but, it's quite hard to not feel like one is trying to understand music by a careful and thorough examination of piano wire.
This is to say that "why do we care about the internals at all?" is a genuinely coherent attitude. The emergent behaviour of the network is, it could be said, synonymous with its identity. This behaviourism identifies a thing as its response to a sufficiently large (and devious) battery of inputs. You have something resembling a spreadsheet at the end which is believed to capture the nature of the thing. But what if we have two networks that agree on every answer but disagree entirely on how to arrive there? One of these may be a ticking time bomb awaiting the right input for detonation.
Our problems, thankfully, are considerably more manageable. Elman's network is of a thoroughly manageable size. Let us try the intuitive approach first. Given that the object of study is basically a logic gate with knobs on, can we reduce this to an honest-to-God circuit diagram that I can replicate with a soldering iron and some burns for my trouble?
Boolean Minimization
The approach is very simple. At any given point in time, the network really has six possible values attributable to it:
- The input,
- The result of the first hidden unit computation,
- The result of the second hidden unit computation,
- The output of the network,
- The result of the previous first hidden unit computation,
- The result of the previous second hidden unit computation,
We can run our entire 3000 bit training set through the fully trained network and accumulate a table that details the following relationship (laid out here in terrible but serviceable notation):
A complication that arises fairly early is that these numbers are real numbers. Figuring out how to represent pi in a digital circuit is not an enjoyable way to spend one's afternoon. We're going to attempt a radical form of quantization. For any value:
- , we consider it to be 1
- , we consider it to be 0
This might seem like an exercise in throwing interpretability babies out with floating point bath waterses. And yet, this is precisely the mechanism used to make large language models runnable on your phone. We just went several, multiple, radical steps further.
Now, you have a very simple table of 0s and 1s that map to other 0s and 1s. A truth table. Given that the input is only three bits wide, there are at most eight possible rows, and a computer can search exhaustively over all combinations of ANDs, ORs, and NOTs to find the shortest logical expression that reproduces each output column. This process is called boolean minimization, and it has been a sordid reality of circuit design since the 1950s — the goal being to implement a desired logical function using as few gates as possible. I used SymPy's Boolean Minimizer.
The minimized expression returned by SymPy is:
With a bit of simplification, those equations can be read more clearly as:
Here is the XOR-inator 1000, in all its profligate glory:
But... where has C1 ran off to? We gave the Elman network two hidden units and used both of them during training. After binarization, one of them turns out to be on the dole. Why is this? I'm not sure, really. But you can come up with several hypotheses, the most likely one is that the optimization method used to train neural networks (calculus, differentiation) distributes what is a 1-bit computation across two neurons because that's the easiest way for it to solve by gradient descent.
So, what is this circuit actually doing? The answer is rather disappointing, I have to say:
- Output 1 if the current bit matches the previous bit, otherwise output 0
- Remember the current bit for old times' sake
Symbolic Regression
One of the hallmarks of good science-ing is reproducibility. Boolean minimization is feasible only for neural networks with parochial aspirations. The Elman network is a sad little church mouse compared to the GPTs and Geminis of the world. I haven't done the math but I will confidently proclaim the statistic that several universes, ours and neighbouring ones, will die of heat death, be reborn, and achieve much the same muddle we started with before we reproduce anything vaguely approximating a circuit diagram like (4.1) for the models you and I pester on a daily basis.
Rather than exhaustively searching over logical gates, which are necessarily binary, symbolic regression searches over mathematical expressions. The appeal is quite self-evident. It sidesteps quantization entirely. Instead of binarizing to truth tables, we work with the network as is. The difference is that the search space is much greater than the one for boolean minimization. No exhaustive enumeration is possible. I attempted to variants of this. For the first one, I constrained the operators PySR was allowed to touch to logical gates. PySR discovered a slightly more complex expression that ultimately simplifies to the same set of operations we discovered using boolean minimization.
I repeated the search after taking off the constraints and the resulting expression becomes this:
Never mind. I'll keep my circuit diagrams.
Language
Now that we know that Elman's network is capable of representing time, the obvious thing to do is to throw it at language. XOR is relatively simple. Given we're in the 1990s, NVIDIA isn't a household name and no A100s are to be had for love or money, we can't quite throw the petabyte-scale training natural language training sets that we throw at models today. We'll have to construct a synthetic alphabet. How would the network handle a sequence where the underlying rules were stretched out over unpredictable durations?
Elman invents an alphabet. He created three consonants (b, d, g) and three vowels (a, i, u). He then creates a rule:
- Every
bmust be followed by onea - Every
dmust be followed by twois - Every
gmust be followed by threeus
ba, dii, guuu. So eloquent it may as well be Python. You can generate a corpus of these fake words:
diibaguubadidiguuu...
You need to decide how to feed the network letters next. There's something very interesting about letters and numbers. They seem like they should belong in the same category of things but they also feel like they don't. Thinking about this is not straightforward.
Imagine a goblin confined to a lighthouse. The goblin is sentient in that he is capable of setting goals and acting on those goals but is largely limited in scope. He is, however, very conscientious about a task that, for reasons even he does not know, he performs every hour until the end of time. He possesses a rule book that states that he must make a series of signals using the lighthouse lamp.
Unbeknownst to him, the race of men sees the strange lighthouse and the signals broadcast from the lighthouse. Alice, after much careful study, has come to the conclusion that the signals detail the molecular chemistry of a number of compounds. Bob, on the other hand, has validated that the signals are genomic data.
This may not seem like much of an experiment but this reveals a few things:
- The goblin has full command of the signal, or the language . He is capable of impeccable use of it without knowing what it means or, more revealingly, knowing whether it has any meaning at all. We could go one step further and posit that he is not being capable of knowing language the same way humans are to begin with. The goblin is simply executing a sequence of mechanical instructions.
- The symbols contained within have no intrinsic semantic content.
- Interpretation requires defining some interpretation function that maps the expressions of into a domain .
- Crucially, you can define multiple , as Alice and Bob have demonstrated.
- Extra crucially, the validity of is not constrained by the language, it's constrained by the domain you are mapping it into. The only way your interpretation function breaks is if it produces some incoherence or nonsensicality in . For instance, if Alice suddenly saw the lighthouse broadcasting a compound that simply cannot exist, her interpretation function is simply not valid. To repeat, it breaks not in signals, but in the domain of chemistry itself, which has a structure that the interpretation can respect or violate. The adequacy of Alice's interpretation was never a question about the lighthouse. It was always a question about the terrain she was mapping it into.
- The goblin, bless his heart, seems very well versed in chemistry and biology and a number of other fields without being able to tell a quark from a baby triceratops.
This is a foundational idea in logic: Tarski's semantic theory of truth. In fact, we can extend this (in a thoroughly would-not-stand-up-in-court way) to an even more foundational result. Can the goblin broadcast the meaning of the signals using the signals themselves?
Suppose the goblin is struck by a sudden bout of intelligence. He begins carefully communicating a dictionary of what each symbol means (his ) via his signals. But one of two things will happen eventually:
- The definition will become circular. The meaning of a signal will depend on signal which will depend on signal on and on until it loops back on to depending on the meaning of some previously defined signal.
- You will encounter a symbol that you simply cannot define.
This is an even more foundational result of Tarski's: the Undefinability Theorem, a semantic counterpart to Godelian incompleteness. The impasse that the goblin finds himself in is so severe precisely because of the nature of symbols. The only operation defined on the set of all symbols in his language, assuming we grant the Law of Identity, is identity:
i.e. every symbol in the language is itself.
And identity is a miserly inheritance to be left holding. It will tell you that is , and that is not , and then it folds its arms and says nothing further. What it will never tell you is that is nearer to than it is to — and nearness is the very stuff that meaning is made of. "Scarlet" lives next door to "crimson" and a long bus ride from "cerulean." Nobody had to be told this; and no amount of glaring at the three words as symbols — as marks, as tokens, as bare s and s — will ever recover it.
A more startling property of language that a symbolic understanding of language fails to capture lies inconspicuously strewn about throughout your day: counterfactuals. We can create them endlessly and with startling ease — at age 3 if the johnnies in lab coats are believed. What is entailed in the manufacture of a counterfactual? Well, at the minimum, you have to locate a set of symbols that is, in some sense, nearest to a world where some proposition has been negated.
Try it: "If you'd left five minutes earlier, you'd have caught the train." To weigh that, you don't ransack every possible morning — the one where you wore a different coat, the one where the trains run backwards, the one where gravity was momentarily suspended for working on a Sabbath. In fact, you reach with no apparent difficulty, to the morning that differs least from this one and still gets you out the door on time. That reaching-for-the-nearest is not a parlor trick of the imagination — it is a comparison of distance between whole worlds, performed instantly and without instruction. And distance is exactly the one thing a bare symbol cannot hold. is not nearer to than it is to ; is simply , an island unto itself, indifferent to its neighbors. So the moment you so much as frame a counterfactual, you have already reached for the very thing identity refuses to provide: an ordering of how alike things are.
And the trouble is not confined to counterfactuals. Even plain, declarative words refuse to sit still. "Tall" promises one height of a jockey and quite another of a basketball player; "soon" is a brisk few minutes in a kitchen and a few million years in a geology seminar. A word arrives meaning whatever the company around it needs it to mean — and identity, which knows only same or not same, has no machinery for a thing that is the same word and a different size each time you meet it. The natural reflex is to patch this with more rules: very well, write down that "tall" shrinks around basketball players, and ten thousand footnotes besides. But we have already watched that fail. When the goblin tried to define his symbols with his symbols, he hit a circle or a wall — not for want of cleverness, but because there is no finite rulebook lying underneath a language, pinning each word in place. Every word borrows its meaning from every other, and the instant you revise one the rest shift their weight. There is no bedrock. "Just write more rules" is not laborious; it is chasing an exact object that was never there to be caught.
So what is a word's meaning, if not a definition you could fit on a well-appointed dictionary? Something in a truly relational sense — what it entitles you to say next, what it quietly commits you to, what it forbids. "It's a dog" licenses "it's an animal," rules out "it's a prime number," and leans expectantly toward "it might bark." The meaning is that bundle of pulls and prohibitions, held in tension against every other word's bundle. (Hold on to this; a certain tree diagram is going to make it embarrassingly literal before long.) And notice what every one of these properties has in common — nearness, betweenness, degree, the pull of context, the web of commitments. None of it can be read off a symbol by staring at it, and all of it is exactly what you get for free from a space. "Warm" sits between "hot" and "cold" not because a rule decreed the order but because of where it lies; you can walk from the one to the other and pass through it on the way. A symbol must have every such relation bolted on from outside, axiom by laborious axiom, forever — and by the rulebook's own failure, the axioms can never be finished. A space simply has them, by being a space. Meaning, it turns out, does not live in a list. It lives in a geometry.
The discerning reader may by now have deduced that the goblin is an allegory with uncomfortable similarities to every form of AI we currently possess. He has flawless command of the signal and not the faintest idea what it means — and we were careful never to settle whether there is anything to understand beneath the performance, or whether the performance is the whole of it. This is precisely the disquiet a fluent language model provokes: it shuffles symbols with superhuman grace, we keep demanding to know what it understands, and the honest answer may be that the question is malformed, because understanding was never a separate ghost crouched behind the competence.
And here the allegory turns its blade on us. If meaning is a geometry of patterns and not a dictionary of symbols, then you are a goblin too. When I hand you a sentence I am handing you marks, and trusting that the pattern they kindle in your skull lands somewhere near the one in mine. But those patterns are physical, private, grown from a lifetime of data that was never yours and yours alone — they have no reason to coincide exactly, and statistically they never do. We manage a serviceable overlap for the crude and the consequential — "drink water," "mind the step" — and fray into mutual approximation for everything subtler. Two people earnestly disputing "freedom," or "the nature of the universe," are, strictly speaking, two lighthouses signalling past each other, each running a private interpretation function and hoping. Wittgenstein arrived here long before the neural networks did: meaning is use, meaning is relational, and there is no inner dictionary to settle the account. The most telling property of a model like ChatGPT — polysemanticity, where a single neuron carries many unrelated meanings at once — is not a defect we have yet to engineer away. It is what relational meaning looks like when you finally pry one open.
Which leaves us with an awkwardly practical question. If meaning lives in a space — ordered, graded, continuous, relational — and our symbols are bare beads that can only be themselves or not themselves, then we have been handing our machines the one instrument built to miss. Symbols give you identity and difference and nothing further. A space gives you distance, betweenness, direction. And there is exactly one familiar thing assembled from the ground up to carry distance and betweenness and direction, whose rules — unlike a language's — are fully known and mechanically obeyed.
The obvious conclusion here is to convert the words to numbers. Each letter is made into 6 bits of information, designed to embed its various attributes. Some bits will represent whether the sound was a consonant or a vowel. Other bits represent whether the sound was "voiced" or "high." Once again, we feed the network 6 bits at a time and ask it to predict the next one.
The network learns the underlying rule perfectly.
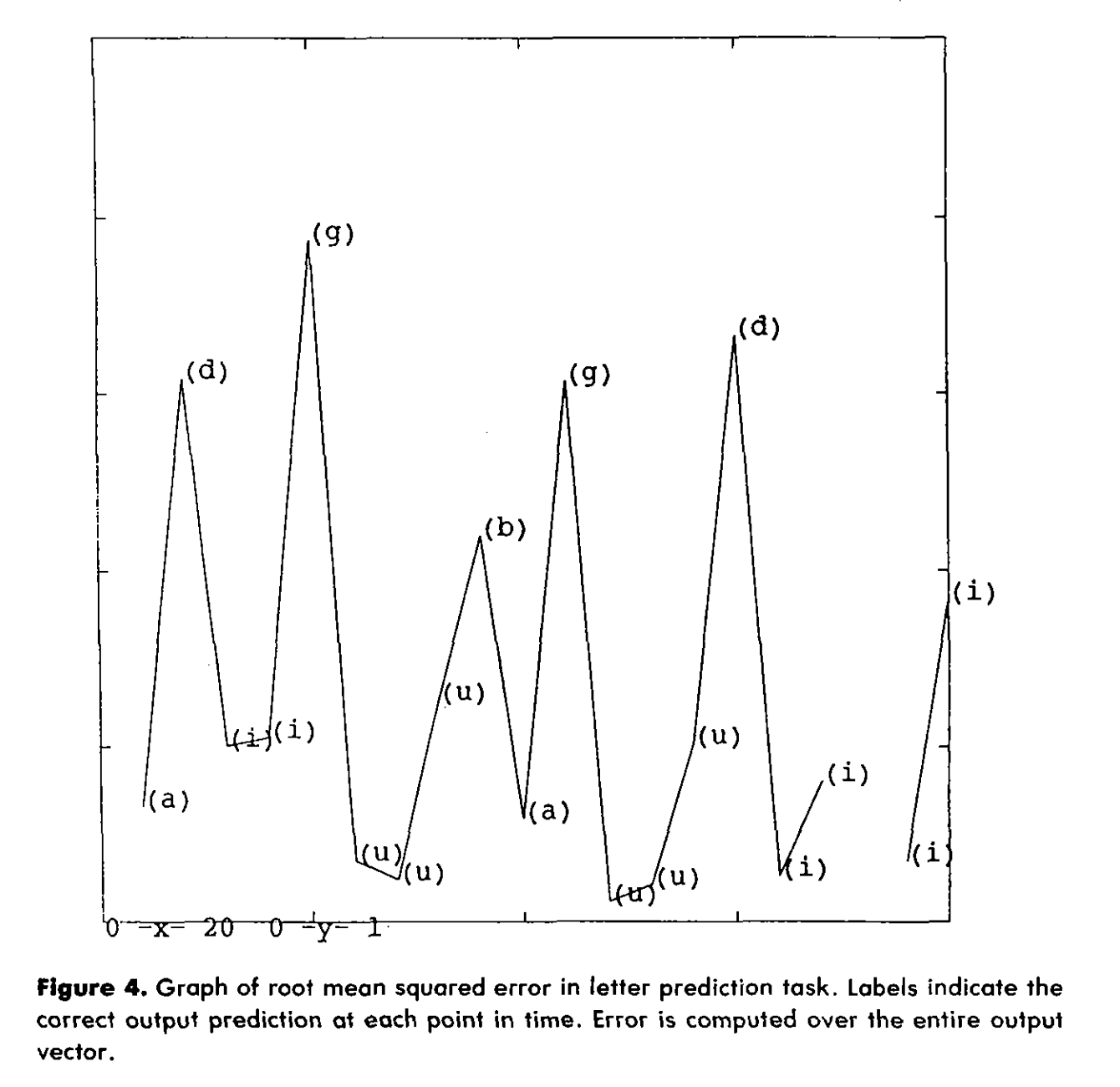
We may be tempted to stop here, but it is worthwhile to look at what the error rate is bit by bit. We can actually plot this error rate:
The first bit encodes whether the output is a consonant or a vowel. The network knows after processing a vowel, that the next letter is a consonant — it just doesn't know which because that is truly random. While it couldn't (and shan't be expected to) predict the exact consonant, it has learned a very low-resolution idea of a consonant and a functional expectation for syntax.
In the beginning was the word...
How do the youngins learn language? Most of the tools that we use to learn — memorization, repetition, writing — are simply not available to infants. From within their tiny skulls, the world is, for all intents and purposes, auditorily a river of noise. How do you make a leap from noise to words? Are we calculators with the wetware receptacles for "words" just waiting to mature or activate?
Elman wonders if the concept of a word could simply be discovered through time. More precisely, word-like categories could be discovered by forecasting into the future. By the act of predicting what comes next, you're forced to build internal states that contain regularities like words. It's worth contemplating the implications of this claim in 1990. Connectionist models, it is possible, could be used not just for static problems that you can bottle up or represent as a "problem unit"; it can be trained, given sufficient capacity and training, to experience the world much the same way we do.
He begins by generating 200 English sentences using a 15-word vocabulary. The sentences were quite simple:
many years ago a boy and a girl eat bread
He removes the spaces and punctuation, turning the text into a stream of letters. He converted each letter to a sequence of bits, feeds the network one by one, and asks it to predict the next letter. He converted the letters to binary vectors, fed them to the network one by one, and asked it to predict the next letter.
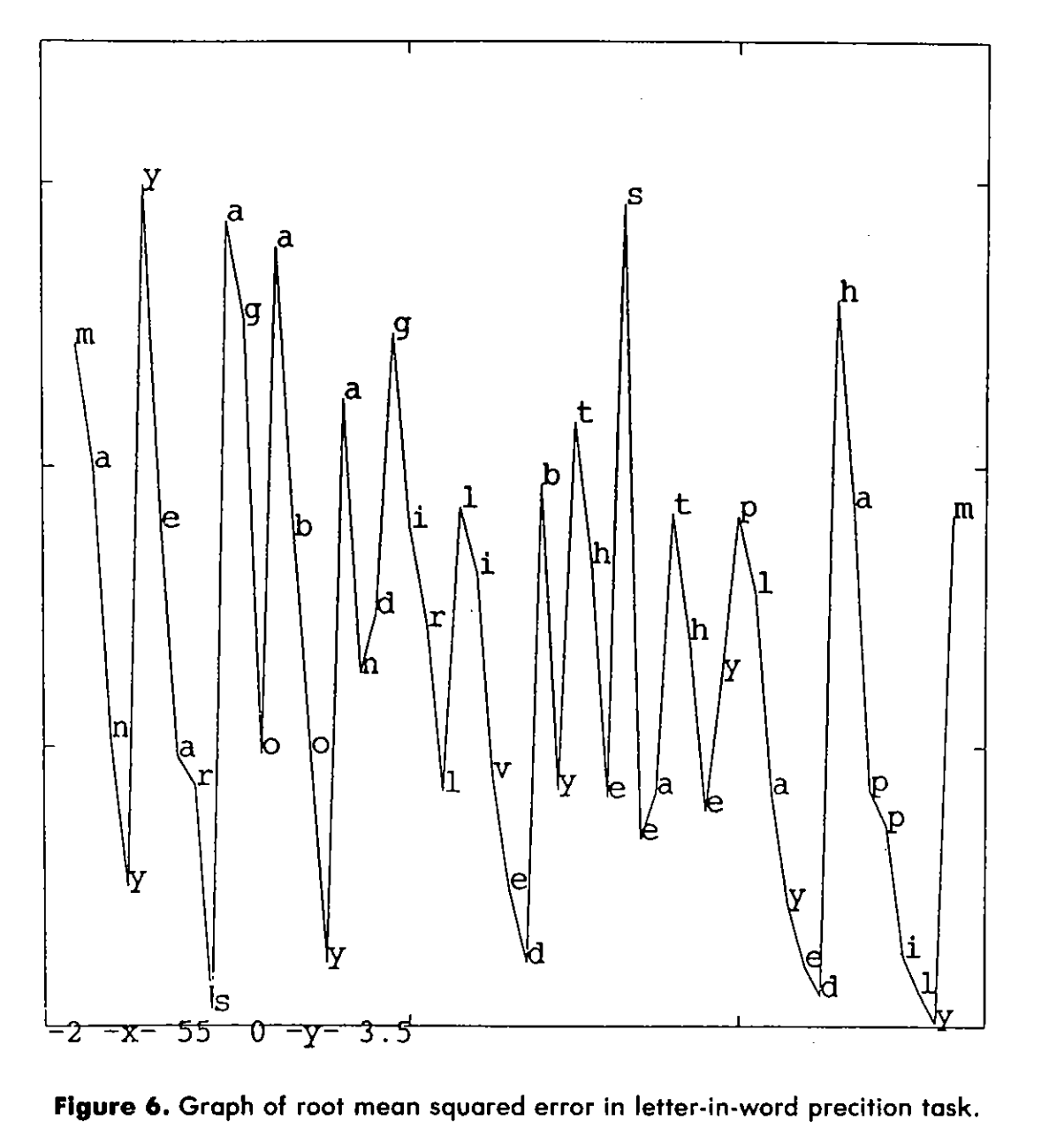
Half the art in this realm lies as much in interpreting failure as it lies in interpreting success.
At the start of a word, the network's error rate is high. If you give it the letter m, the next letter could be a, o, u, e — it's a crummy affair. But once the network sees m a, the possibilities narrow. Once it sees m a n, it is almost certain the next letter is y.
But after the y, the word is over. You wills see that the error rate spikes after that. The network cannot predict. Without ever being told what a "word" is, without any spaces, dictionary, or symbolic rules, the network's own error rate naturally drew boundaries around the words. The spikes in unpredictability became the spaces between words. The network discovered the concept of a word simply by paying attention to the statistical rhythms of time.
Semantics
I shall not today attempt further to define the kinds of material I understand to be embraced within that shorthand description ["artificial intelligence"], and perhaps I could never succeed in intelligibly doing so. But I know it when I see it, and the simple recurrent network involved in this case is not that.
Much of what Elman has done unto this point could be argued away as statistical monkey business. The fundamental issue with any form of machine intelligence is that it is an exercise in optimizing towards something we don't actually know the shape of. More tantalizingly, we can seemingly conceive of entities fortunate physically and functionally identically to us that lack consciousness.
And if we cannot definitively know what consciousness is, if the very shape of intelligence remains as elusive as ever, then it stands to reason that hand-coding our way to machine intelligence is likely to be a fruitless endeavour. Children don't receive a rulebook upon birth; never mind that they wouldn't be particularly inclined to consult it. They internalize invisible patterns from the raw material of sense data.
The logical next step is to take our Simple Recurrent Network and give it actual language and see if it can understand highly abstract concepts that humans manipulate by first nature:
- A noun is a person, place or thing.
- A verb is an action.
- Transitive verbs require some direct object. "The rock ate the cat" is grammatically valid but semantically impoverished.
Elman categorizes 29 words into different classes.
- Nouns were split into categories: Humans (man, woman), Animals (cat, mouse), Breakables (glass, plate), Food (cookie, bread).
- Verbs were split into categories: Intransitive (sleep, think), Transitive (see, chase), Destructive (break, smash), and Eating (eat).
He then wrote a program to generate 10,000 random two- and three-word sentences using valid grammar and logic. ("Man smash plate." "Cat move." "Dragon eat girl.")
Crucially, he took these 29 words and represented each of them as a completely blank, randomized 31-bit vector. There was absolutely no mathematical similarity between the vector for "man" and the vector for "woman". There was no "human" bit. There was no "verb" bit. All the network saw were meaningless barcodes.
He fed the 10,000 sentences into the network in an unbroken stream. Predict the next word.
This task is fundamentally impossible to get perfectly right. If the input is "woman," the next word could be "smash," "sleep," "eat," or "think." The network will always have a high error rate. However, Elman realized that a smart network shouldn't try to guess the exact word. A smart network should learn the probability distribution of the next word. It should learn to activate the output nodes for all valid verbs, and suppress the output nodes for all nouns.
After training the network, Elman wanted to see what was going on inside its "brain." He paused the training. He then fed every single word into the network, one by one, in its various contexts, and recorded the exact mathematical state of the network's Hidden Layer.
He took all these hidden layer states and ran a hierarchical clustering algorithm on them. Essentially, he asked a computer to group the network's internal "thoughts" based on how mathematically similar they were to each other.
The resulting graph is the crowning achievement of the paper.
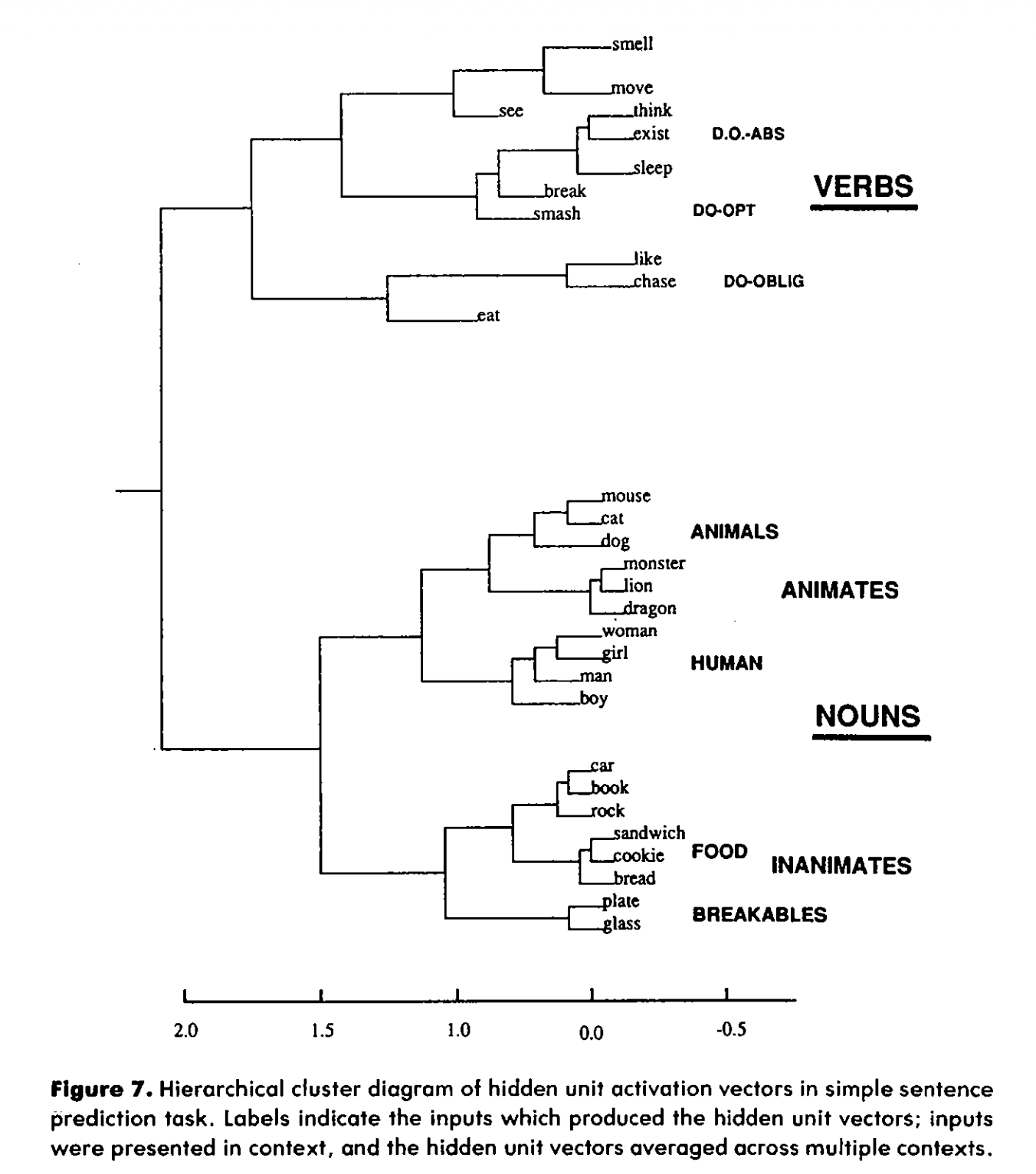
Without a single line of symbolic code, without ever being given a dictionary or a grammar textbook, the network had perfectly reconstructed the English parts of speech.
It grouped "break" and "smash" tightly together in its mathematical space, because they behaved the same way in time (they were always followed by "glass" or "plate"). It separated "man" and "woman" from "cat" and "mouse", but grouped them all under the larger umbrella of "Animates," because they could all "move" and "eat," whereas "rocks" and "bread" could not.
The network had deduced semantics from syntax. It had deduced meaning from time. The invisible rules of reality had cast a shadow onto the sequence of words, and the network had traced the shadow back to the rules.
"Zog"
In symbolic AI, if you want the computer to understand a new concept, you have to explicitly bind it to a category. If I introduce a new word, "Zog," and I want the computer to know how to use it, I have to write a rule: Zog = Noun [Human]. This is called the type/token problem. You have to define the type before you can use the token.
Elman wanted to see how his connectionist model handled a brand new token.
He froze the fully trained network so it could not learn anything new. He then invented a brand new word: Zog. He gave Zog a random, meaningless barcode vector. He then created a new set of sentences, but everywhere the word "man" would have appeared, he substituted "Zog". ("Zog eat bread." "Zog sleep." "Monster chase Zog.")
He ran these new sentences through the frozen network and looked at the hidden layer activations.
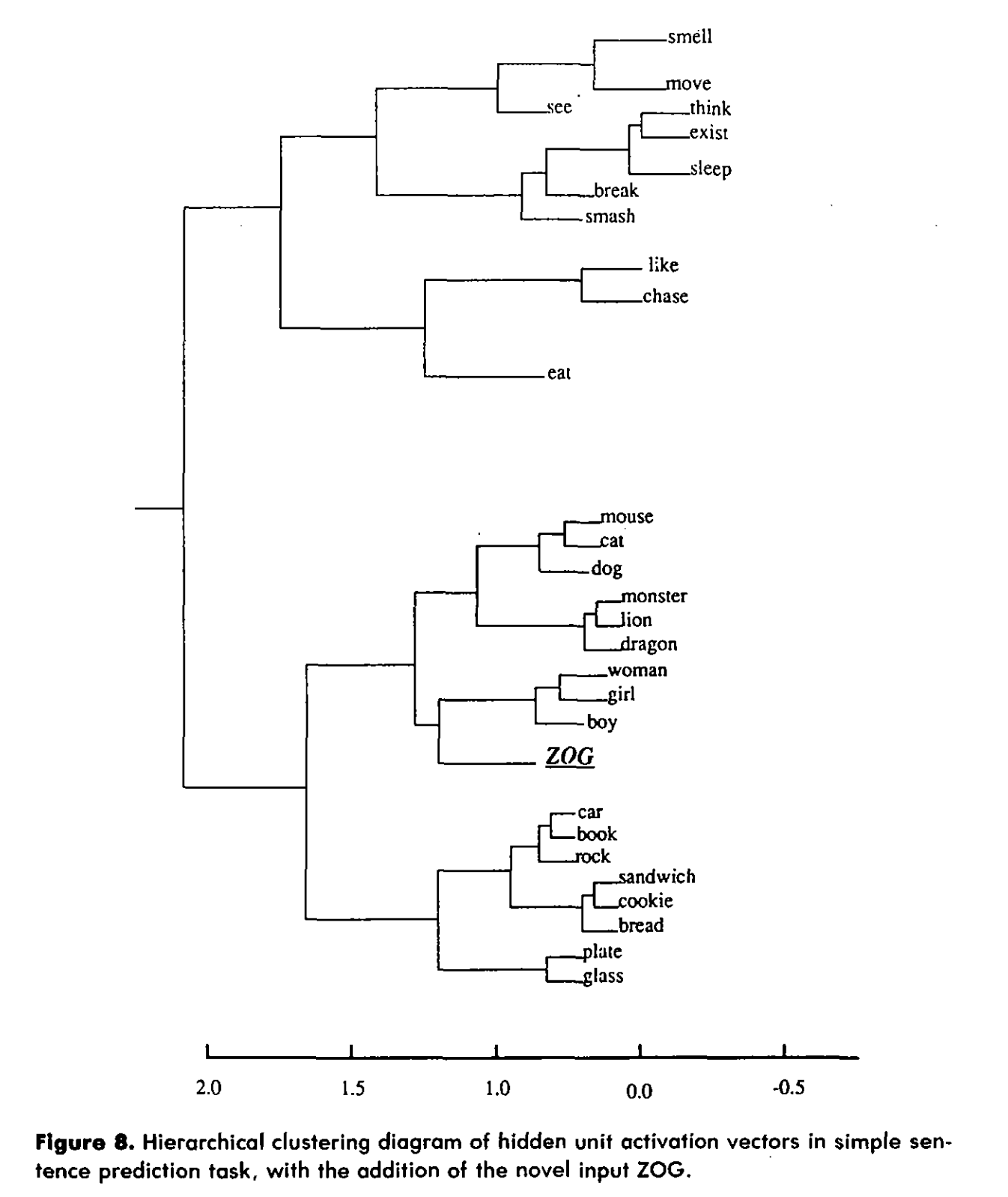
Zog in the vector space: a new word, never seen during training, is instantly placed alongside the human nouns, entirely from the company it keeps.
The network instantly understood Zog. Because Zog was followed by verbs like "sleep" and "eat," and because Zog found himself pursued by monsters on occasion, the network's internal processing routed the mathematical representation of Zog directly into the "Human Noun" cluster.
The network did not need an explicit rule declaring what Zog was. The context of Zog in time automatically defined its meaning in space.
As Elman wrote, this solved the type/token problem without symbolic binding: "The network structures that space in such a way that important relations between entities is translated into spatial relationships... Every item may have its own representation, but because the representations are structured, relations between representations are preserved."
The Legacy of Time
Jeffrey Elman published Finding Structure in Time in 1990.
In 1990, Germany was still suffering from a terrible case of split personality disorder. Typewriters, communism and worse, acid-washed jeans were the order of the day. He proved three vital things that form the bedrock of modern AI:
1. Time is not a dimension of input; it is an effect on processing. You do not need to give a computer a timeline of events. You simply need to give it a dynamic memory and let the continuous present flow through it. The past alters the state of the machine, and the machine views the future through that altered state.
2. The error signal is the ultimate teacher. Elman showed that a network doesn't need to be told what it is looking for. By simply assigning it the task of predicting the immediate future, the network's own failures (its error rates) force it to reverse-engineer the structure of the data.
3. Meaning is a byproduct of context over time. A neural network does not need to know what a "noun" or a "verb" is. It does not need to know that humans eat bread and rocks do not. If you feed it enough sequences of temporal data, the network will physically organize its internal architecture to reflect those realities, because doing so makes predicting the future mathematically easier.
Beyond the academic value of the paper, it is also worth considering the writing style of the paper. It does not read like academic output today. It captures the story of a man in the act of understanding rather than presenting.
The architecture has grown exponentially more complex. Elman’s SRNs evolved into LSTMs (Long Short-Term Memory networks), which eventually gave way to the Transformer architecture that powers modern Large Language Models. We went from networks with 150 hidden units predicting a vocabulary of 29 words, to networks with trillions of parameters predicting the entirety of human knowledge. But the philosophy remains entirely unchanged.
I encourage you to read it.
Further Reading
- Claude Shannon, A Symbolic Analysis of Relay and Switching Circuits. While technically a masters thesis, the quality of writing in this foundational text in what is usually a dry subject is comparable to that of Finding Structure in Time. He argues that the laws of logic and the laws of electricity are one and the same.